自宅のKubernetesにGPUノードを追加した
ChatGPT周りが面白かったので、LLM関連を学習したくなり、久しぶりにPCを自作した。 最近はNUCやらDeskMiniなどのベアボーン、ラズパイばかり触っていたので自作PC周りはなかなかの浦島太郎状態。
ブログのエントリをあさってみると2007年のPC環境で自作PCをデスクトップに使ってるのを発見できた。グラボはATIしか買った記憶はなかったのだが、GeForce 7900 GS とか使ってる。。謎だ。
HW
自作PCは久しぶりということもあって全く状況が掴めなかったのもあり、一瞬、どこかのPCショップのBTOでも買うかと日和った考えが頭によぎったが、最近、自転車の組み立てで自分で組むのは面倒、という理由でショップに任せたところとても不快なめにあったので、自分でできることは自分でしようという気分になりパーツを買い集めた。

- CPU: Intel Core i5 13400 BOX
- 32,640円
- MB: ASUS TUF GAMING B760M-PLUS D4 (B760 1700 MicroATX)
- 26,446円
- Memory: Crucial CT32G4DFD832A DDR4-3200 32GB x2
- 21,300円 x 2
- SSD: Crucial P5 Plus CT1000P5PSSD8JP (M.2 2280 1TB)
- 12,660円
- GPU: NVRTXA4000 [NVIDIA RTX A4000 16GB GDDR6]
- 135,800 円
電源とケースは使い回し。自作PCは久しぶりなはずだが、電源とケースが余っているのが謎だ。
SW
OSインストール
- OS: Ubuntu 22.04.03
- Container Runtime: containerd
- Kubernetes: v1.24.6
OS は Ubuntu 22.04 を選んだが、そのままインストールすると途中で処理が止まりインストールできず。少し焦った。
最新のカーネルのバックポートを利用してインストールする必要があったようだ。 メモ: Boot and Install with the HWE kernel 。
OSをインストールしたらそのまま containerd/kubelet をインストールしてクラスタにジョイン。
GPU のドライバのインストール
Kubernetesクラスタの一員になったのでドライバのインストールも GPU Operator に任せる。
ノードの名前は poissonnerie。ドライバやFeature DiscoveryはGPUノードにだけいればいいので、いい感じにラベルとtaintをつける。
k label node poissonnerie unstable.cloud/nvidia-gpu=yes
k taint node poissonnerie nvidia.com/gpu=:NoSchedule
インストールはhelmから直接せずに一旦templateでファイルに落としてからkustomizeをかける。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
# renovate: datasource=helm depName=gpu-operator-chart packageName=gpu-operator registryUrl=https://helm.ngc.nvidia.com/nvidia
CHART_VER=22.9.2
CHART=nvidia/gpu-operator
VALUES=src/values.yaml
MANIFEST=src.yaml
NAMESPACE=gpu-operator
NAME=gpu-operator
helm template --include-crds --version v${CHART_VER} --values ${VALUES} --namespace ${NAMESPACE} ${NAME} ${CHART} > ${MANIFEST}
kustomizeからいきなりhelmを使えるのだが、一旦helmの出力するマニフェストを確認したいので毎回templateで出力してる。
resources:
- src.yaml
patchesStrategicMerge:
- |-
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: gpu-operator-node-feature-discovery-worker
spec:
template:
spec:
nodeSelector:
unstable.cloud/nvidia-gpu: "yes"
こんな感じでyamlを作った後に、kubectl apply -k . でインストール。
✦ ➜ k get pod
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-q57nz 1/1 Running 0 10m
gpu-operator-5df795584-2mknv 1/1 Running 2 (40m ago) 46m
gpu-operator-node-feature-discovery-master-84c7c7c6cf-h7lpf 1/1 Running 0 46m
gpu-operator-node-feature-discovery-worker-tdhs2 1/1 Running 0 11m
nvidia-container-toolkit-daemonset-j6xbw 1/1 Running 0 10m
nvidia-cuda-validator-j9qwp 0/1 Completed 0 8m2s
nvidia-dcgm-exporter-sbw6w 1/1 Running 0 10m
nvidia-device-plugin-daemonset-ddjj9 1/1 Running 0 10m
nvidia-device-plugin-validator-2p4hf 0/1 Completed 0 6m20s
nvidia-driver-daemonset-klfrn 1/1 Running 0 10m
nvidia-operator-validator-f8jr5 1/1 Running 0 10m
いい感じにCPUノードだけで動いてる。
✦ ➜ k get node poissonnerie -o json | jq '.status.allocatable'
{
"cpu": "16",
"ephemeral-storage": "884016022498",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "65483284Ki",
"nvidia.com/gpu": "1",
"pods": "110"
}
"nvidia.com/gpu": "1" がついた。
yuanying@poissonnerie:~$ sudo cat /etc/containerd/config.toml| grep nvidia
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/local/nvidia/toolkit/nvidia-container-runtime"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia-experimental]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia-experimental.options]
BinaryName = "/usr/local/nvidia/toolkit/nvidia-container-runtime-experimental"
GPU Operator は /etc/containerd/config.toml もいじってくるらしい。変に自分で編集しないように気をつけたい。
cat <<EOF | k apply -f -
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- effect: NoSchedule
key: nvidia.com/gpu
operator: Exists
EOF
Getting Started 通りにサンプルアプリケーションをインストール。
✦ ➜ k get pod
NAME READY STATUS RESTARTS AGE
cuda-vectoradd 0/1 Completed 0 9s
✦ ➜ k logs cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
ちゃんと動いた。
Wake on LAN の有効化
GPUは電気を食うので使わないときはシャットダウンしておきたい。ということで同時に Wake on LAN も以下を参考に有効化した。
- Ubuntu 22.04 Wake on LanでリモートのUbuntuデスクトップパソコンを起動する
- LinuxでWake on LAN設定
- [マザーボード] BIOSでWOL (Wake On Lan) 機能を設定する方法
その他
Kubernetes上で Stable Diffusion も動いた。
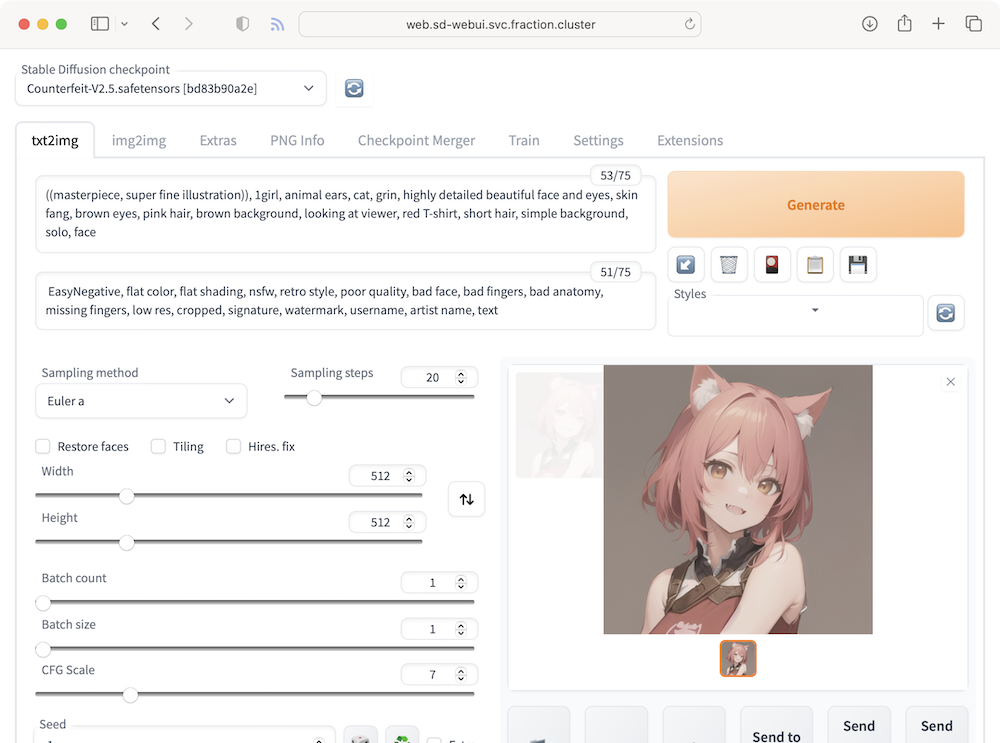
満足したので機械学習の学習をする。